So, as of late, I’ve been seeing a lot of content about locally deploying DeepSeek-R1.
Many netizens have posted articles or videos claiming they’ve successfully deployed and used the DeepSeek-R1 model locally, which is said to rival OpenAI-o1. While it still feels a bit off, since DeepSeek-R1 is an open-source model, it can indeed be deployed locally.
As an RTX4090 user, I’m considered to have a high-end setup among home PC enthusiasts. I figured since so many people have successfully deployed it locally, my setup should be able to handle it too. So, I went to check it out, and well… then I discovered:
Translation is truly a wonderful thing!
If you don’t want to use Google’s web translation, you should really try a translation plugin—Are you struggling to read the flood of English comments on Xiaohongshu? Try Immersive Translate!。
Indeed, DeepSeek released several smaller parameter models along with R1, including 1.5B, 7B, and 8B. But looking at the names, even if you’re not familiar with Llama, doesn’t that Qwen look somewhat familiar? I was about to spell it out in Pinyin.
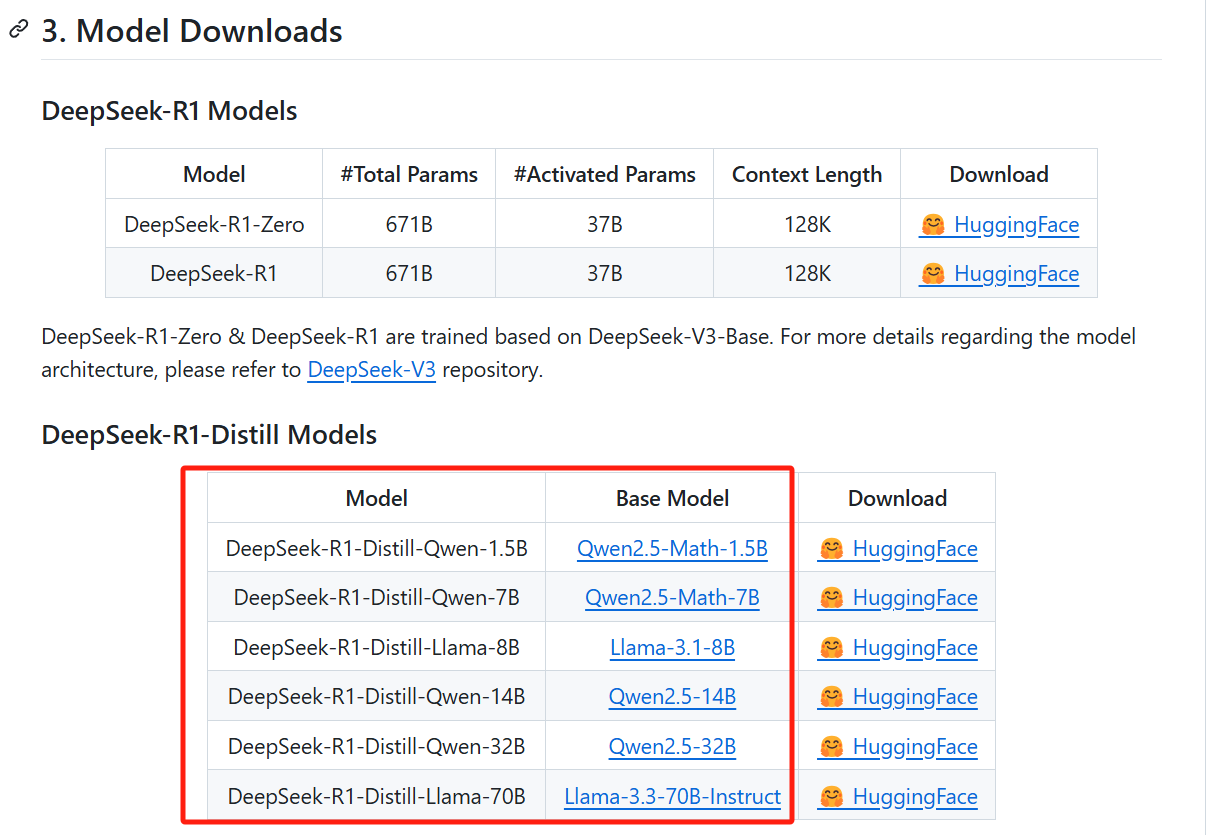
The GitHub and Hugging Face pages state it clearly. If I had to pick one to blame, I think it might be Ollama.
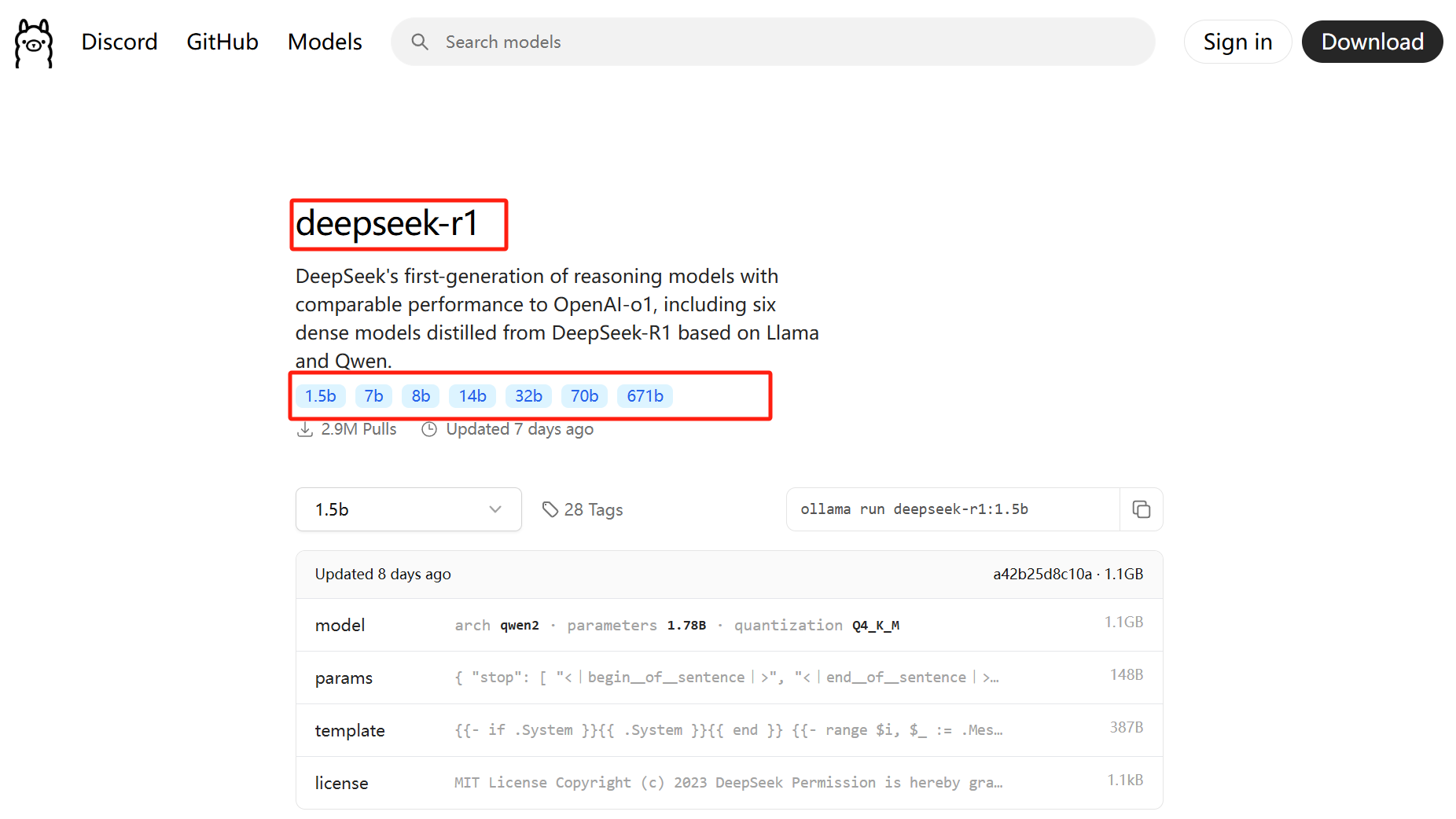
It says deepseek-r1 at the top, and below it lists 1.5b/7b/8b/14b/32b/70b/671b.
But, friends, if you enable translation and scroll down further.
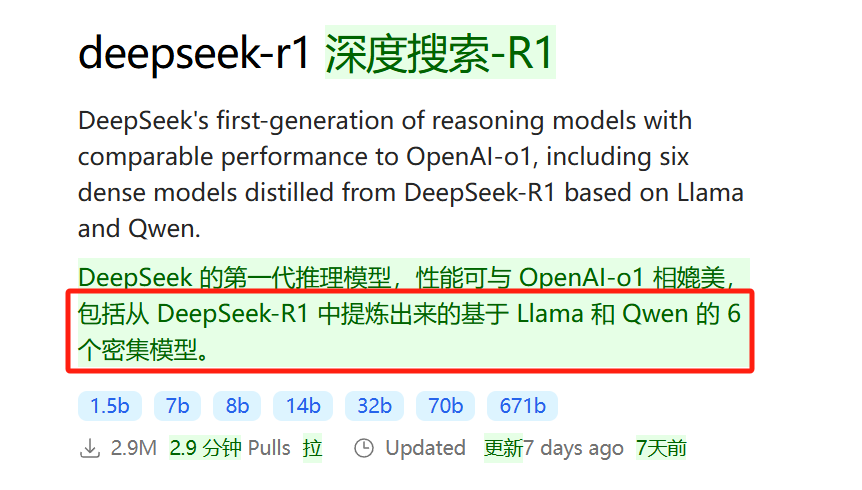
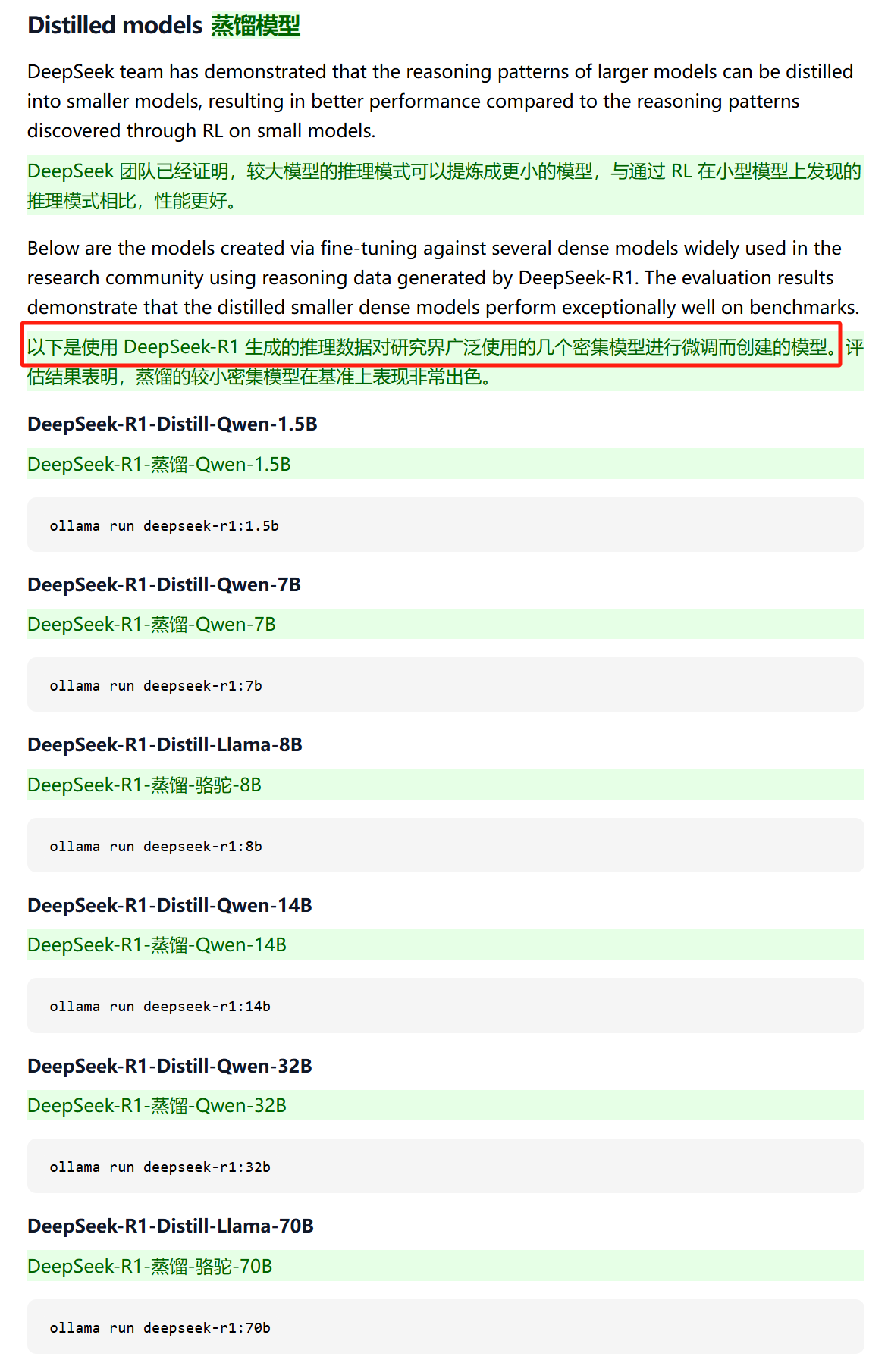
These are models created by fine-tuning several dense models widely used in the research community with reasoning data generated by DeepSeek-R1.
The GitHub page also includes relevant information:


DeepSeek-R1-Distill models are fine-tuned from open-source models using samples generated by DeepSeek-R1. We have slightly modified their configurations and tokenizers. Please use our settings to run these models.
So, the DeepSeek-R1-Distill-Qwen-1.5B model is essentially still Qwen2.5-Math-1.5B; the DeepSeek-R1-Distill-Llama-8B model is essentially still Llama-3.1-8B.
DeepSeek released these distilled models to demonstrate that ‘the reasoning patterns of larger models can be distilled into smaller models, achieving better performance compared to reasoning patterns discovered through RL on small models.’
The true R1 models officially released are only DeepSeek-R1 and DeepSeek-R1-Zero, both trained based on DeepSeek-V3-Base with a parameter scale of 671B:
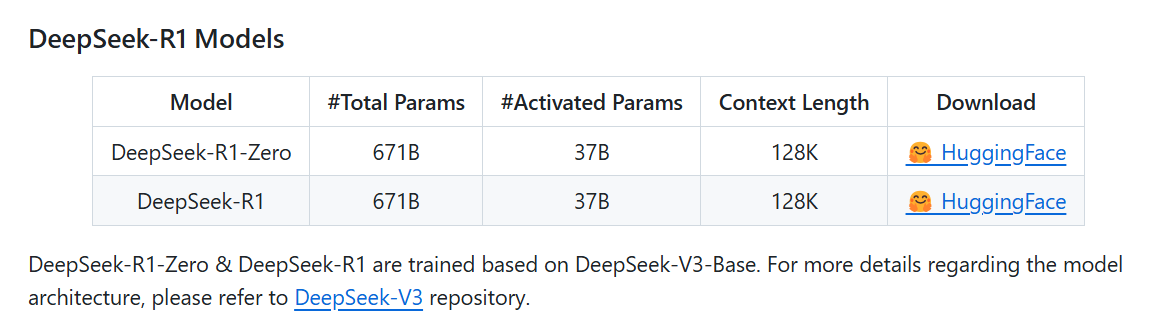
If you absolutely must locally deploy the real R1, you might only try the community-released 1.58-bit precision quantized version of DeepSeek-R1-GGUF. Using a GPU with 24GB VRAM like the RTX 4090 can achieve output speeds of up to 1-3 tokens per second.
So, stop messing around.
The web version is free, and the API isn’t expensive either—why bother?